
Boosting AI Model Inference: Three Proven Methods to Speed Up Your
Transfer Learning: Definition, Tutorial & Applications
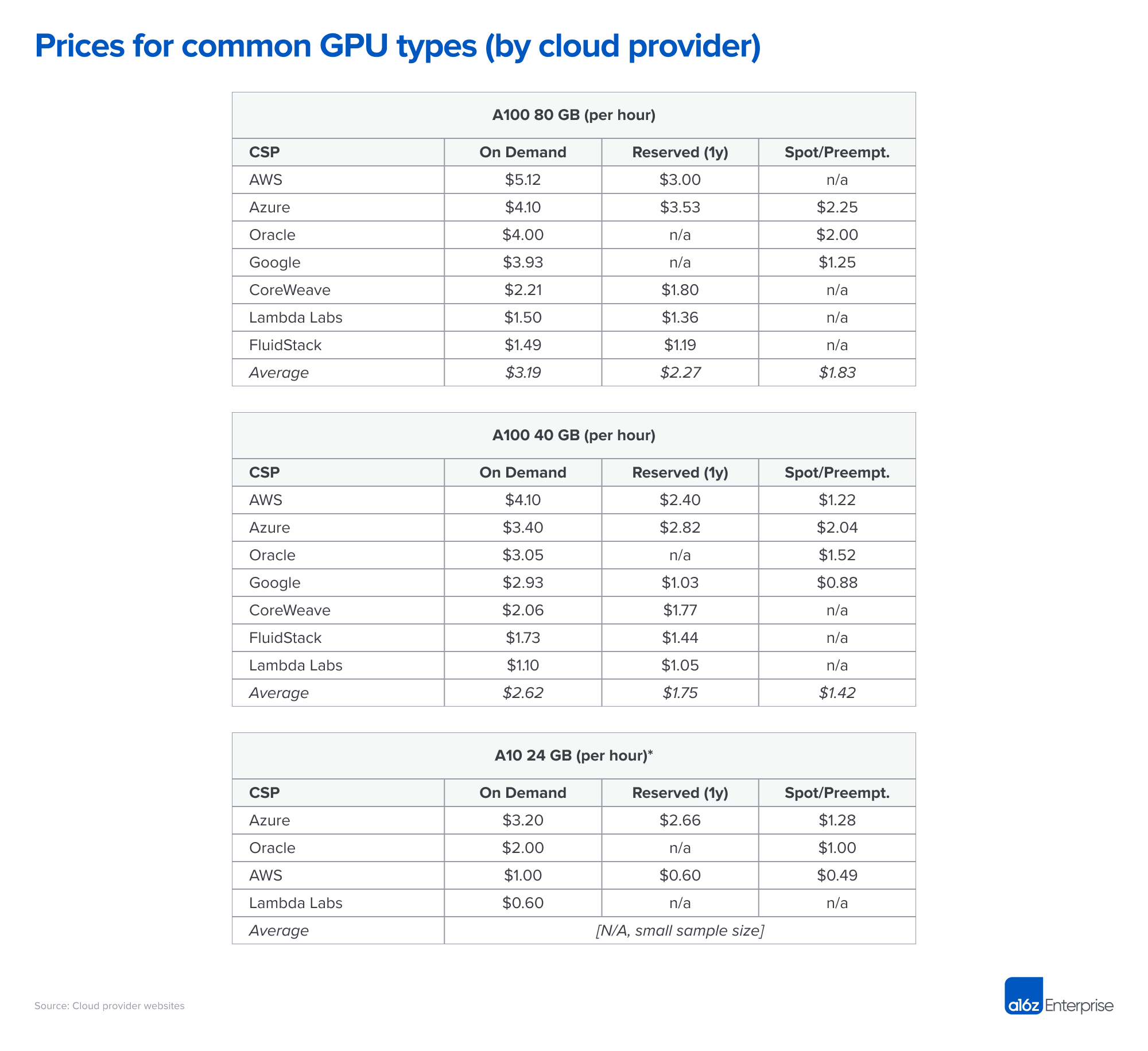
Navigating the High Cost of AI Compute

Winning in the Generative AI Stack: Analyzing Layers and Players
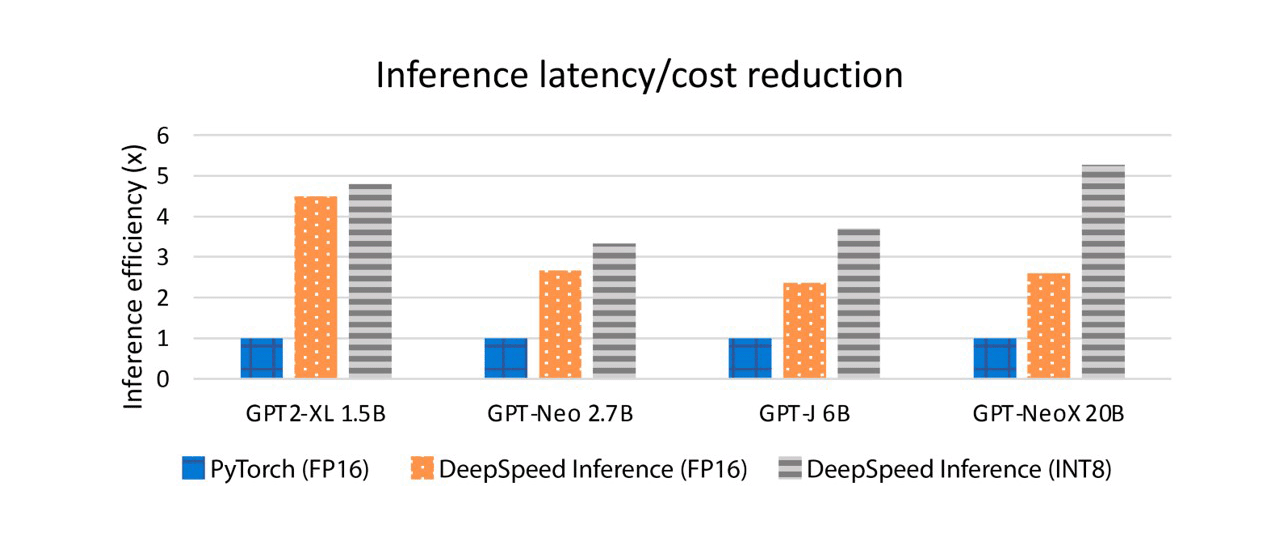
DeepSpeed Compression: A composable library for extreme

DeepSpeed - Microsoft Research: Timeline
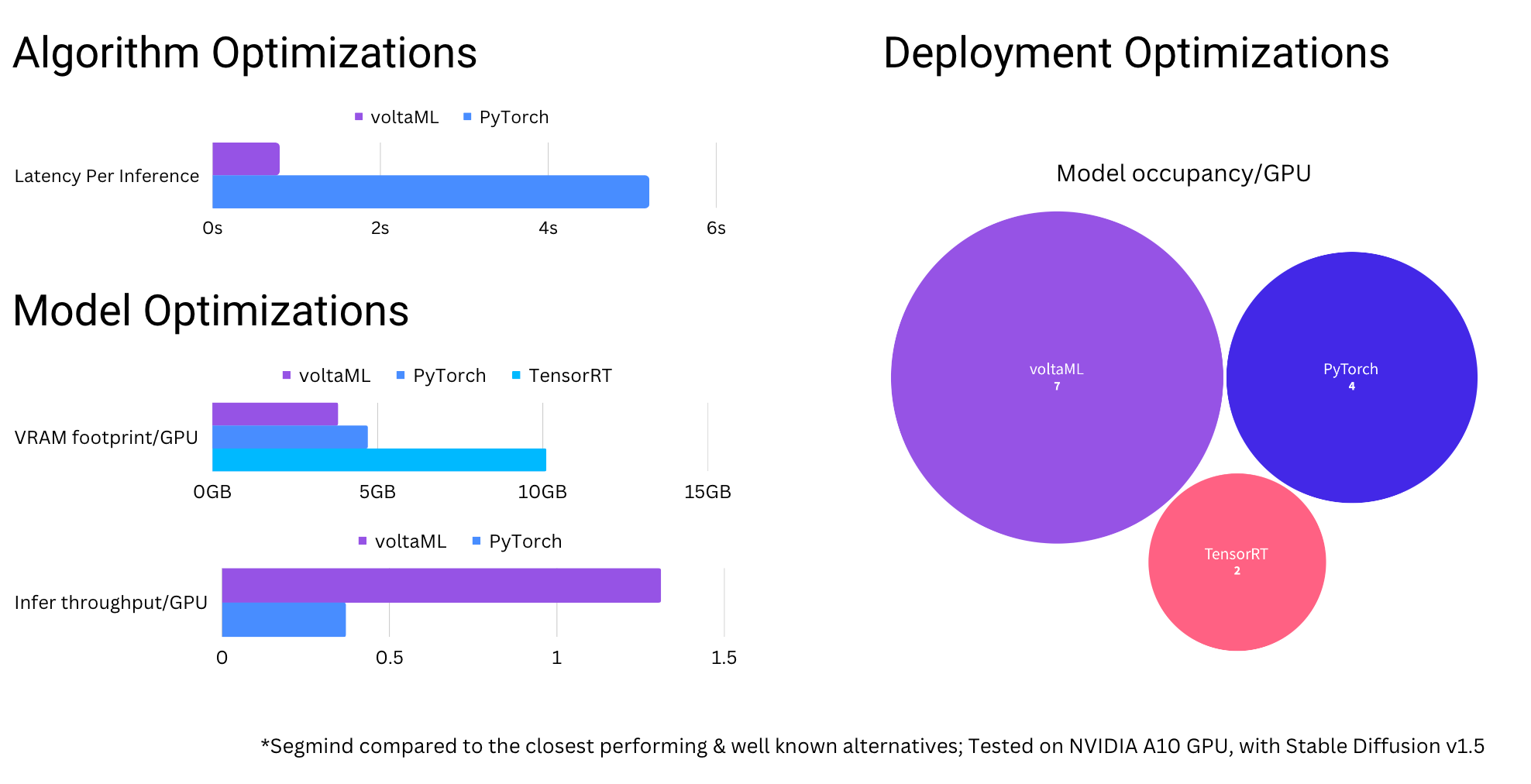
Reduce Inference Cost and Speed Up Machine Learning Models
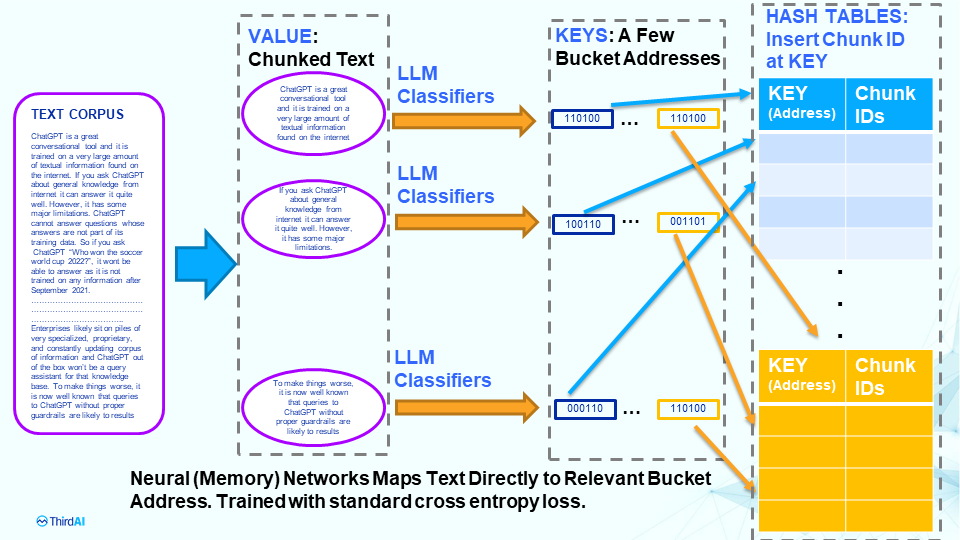
Neural Databases: A Next Generation Context Retrieval System for
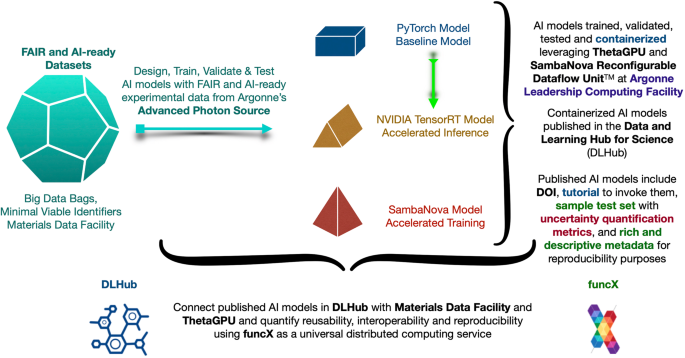
FAIR principles for AI models with a practical application for

Inference Optimization Strategies for Large Language Models

All You Need to Know About Meta's New AI Chip MTIA
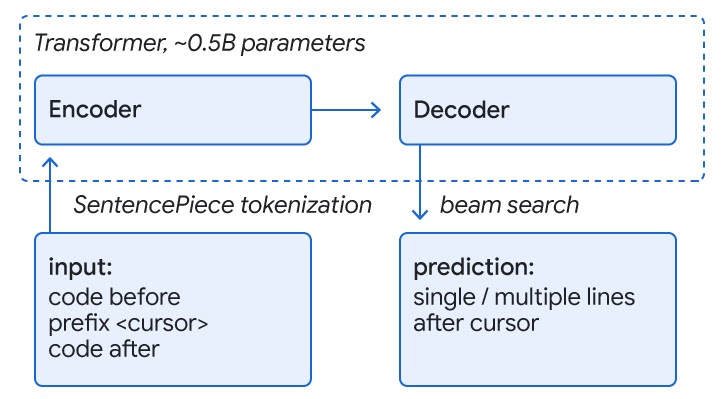
ML-Enhanced Code Completion Improves Developer Productivity

ScaleLLM: Unlocking Llama2-13B LLM Inference on Consumer GPU RTX

Speed up your BERT inference by 3x on CPUs using Apache TVM
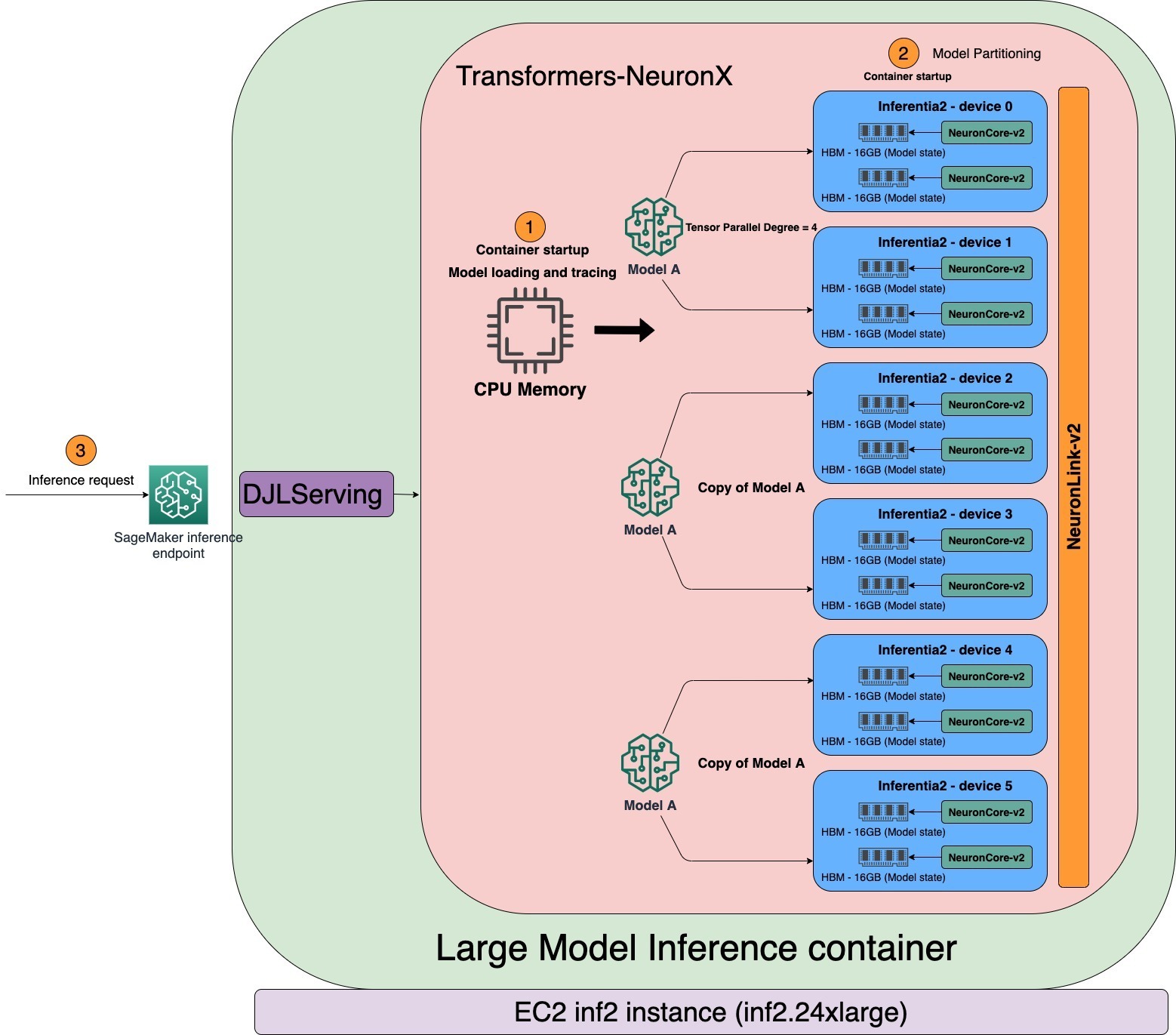
Achieve high performance with lowest cost for generative AI








