
LAMBADA Dataset Papers With Code
The LAMBADA (LAnguage Modeling Broadened to Account for Discourse Aspects) benchmark is an open-ended cloze task which consists of about 10,000 passages from BooksCorpus where a missing target word is predicted in the last sentence of each passage. The missing word is constrained to always be the last word of the last sentence and there are no candidate words to choose from. Examples were filtered by humans to ensure they were possible to guess given the context, i.e., the sentences in the passage leading up to the last sentence. Examples were further filtered to ensure that missing words could not be guessed without the context, ensuring that models attempting the dataset would need to reason over the entire paragraph to answer questions.

Not Enough Data? Deep Learning to the Rescue! - Gao Haojun
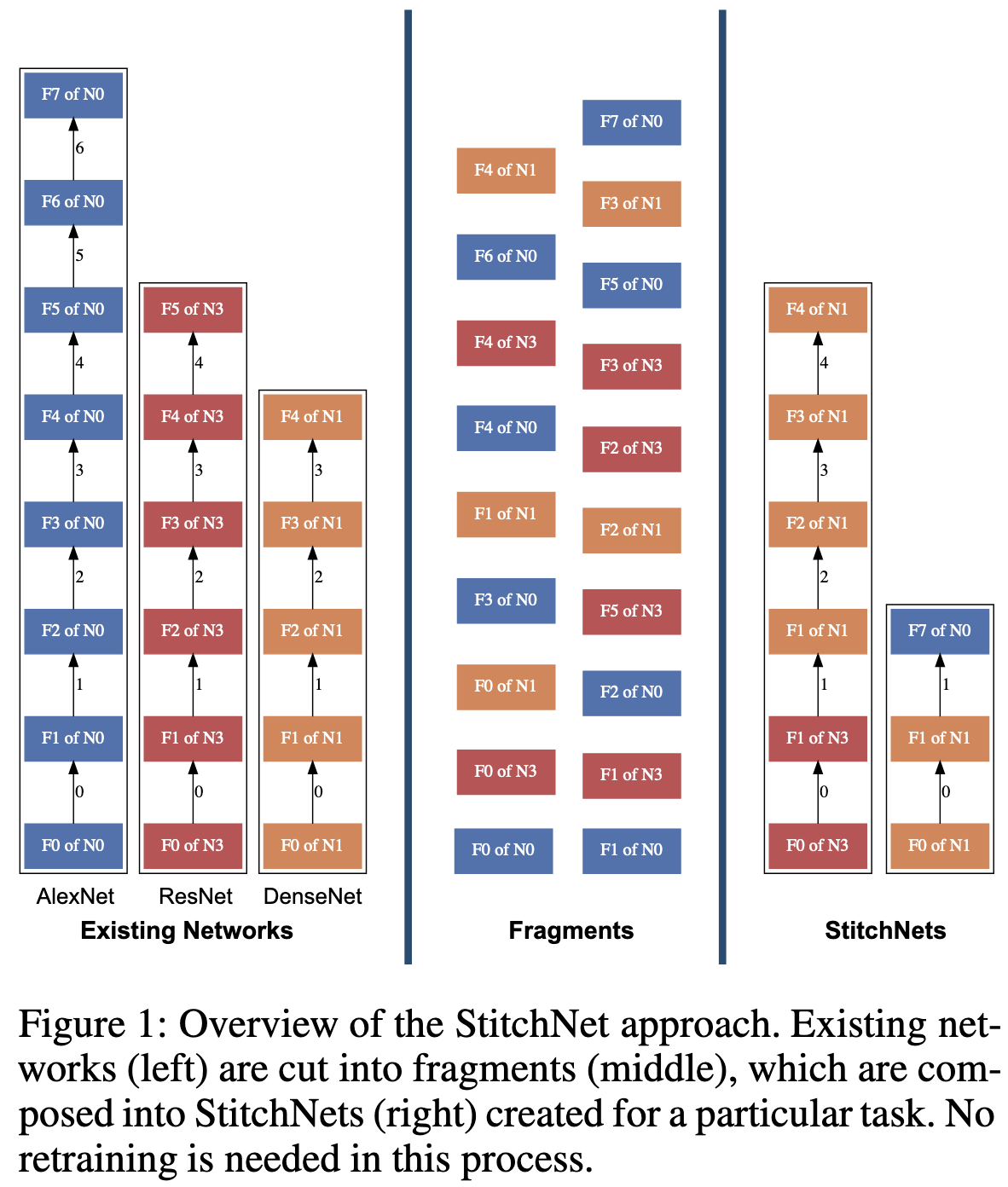
2023-1-8 arXiv roundup: Language models creating their own data

Applied Sciences, Free Full-Text

PDF) Constructing Regression Dataset from Code Evolution History

Data augmentation techniques in natural language processing
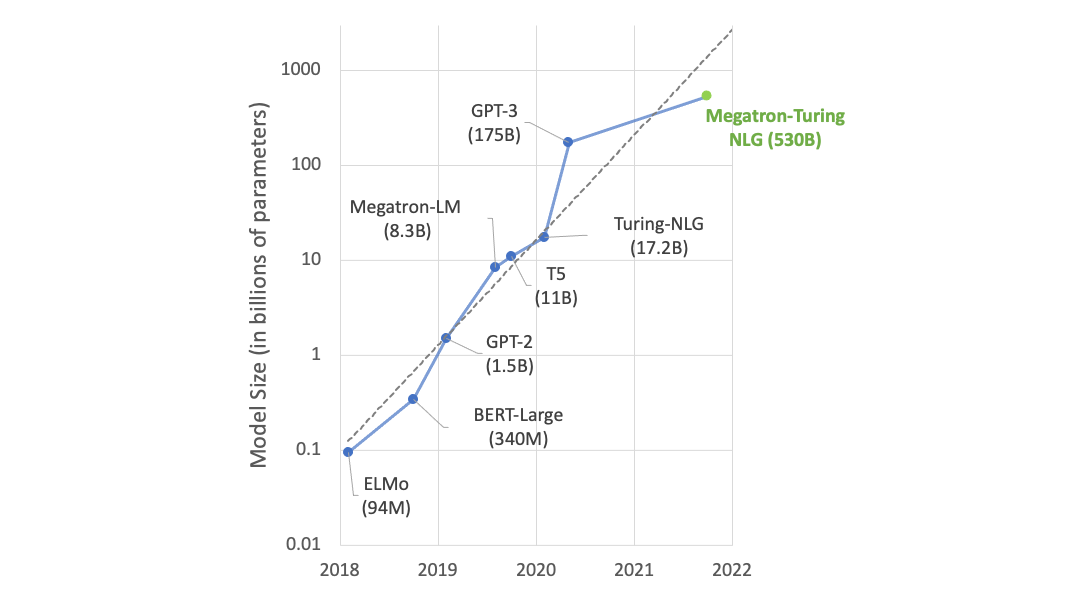
Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B
GitHub - bdhingra/coref-gru: Model for processing text sequences

Basic ORKG schema for papers: Blue shapes are resources and
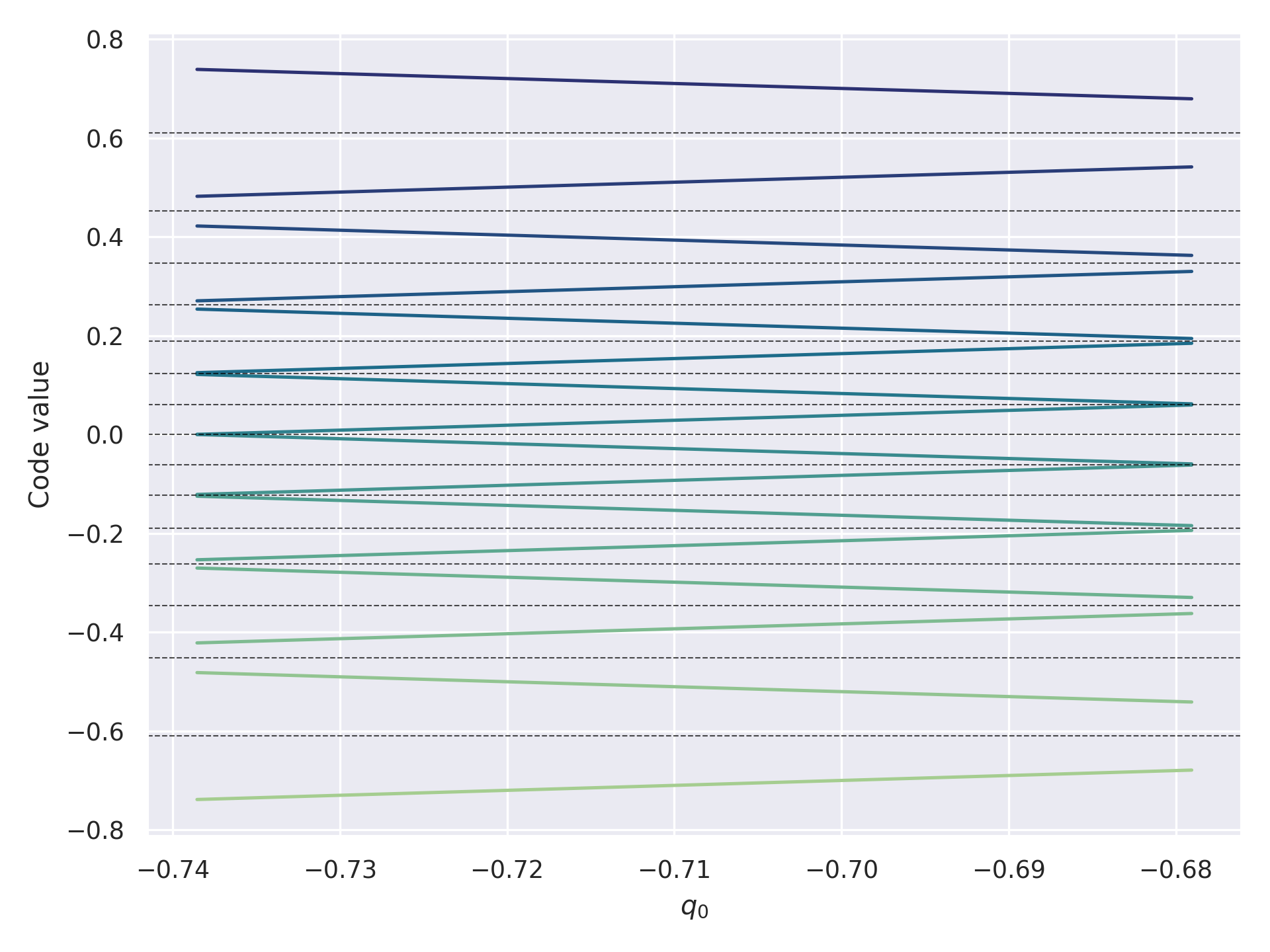
2306.06965] NF4 Isn't Information Theoretically Optimal (and
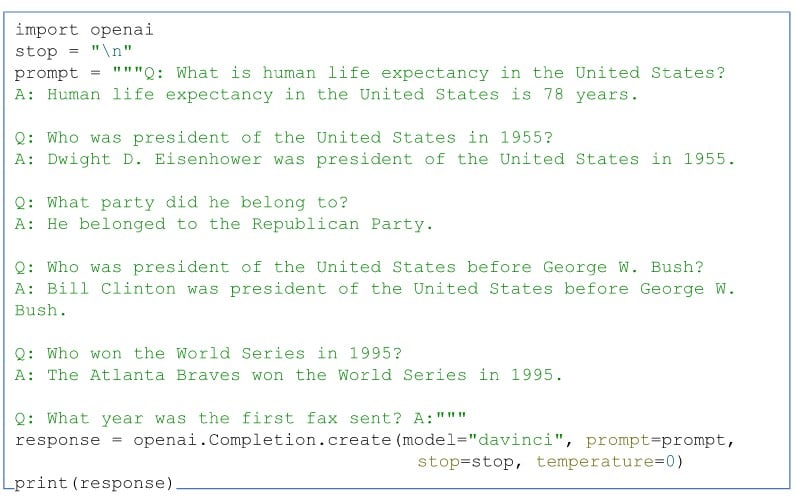
OpenAI GPT-3: Everything You Need to Know [Updated]
LightGPT And 21 Other AI Tools For Large Language Models

PDF] Revisiting Simple Neural Probabilistic Language Models









